Trusted by market leaders · Client results
查询字符串维度捕获的内容
查询字符串(Query String)维度按页面访问时 URL 中存在的完整查询字符串对您的 Core Web Vitals 数据进行分组。这包括 ? 之后的所有内容:跟踪参数(如 utm_source=google)、分页(如 page=2)、排序(如 sort=price)、搜索查询(如 q=running+shoes)、A/B 测试变体以及过滤器组合。
大多数性能监控工具会剥离查询字符串或将其合并到单个 URL 组中。CoreDash 将它们保持完整,这意味着您可以在同一页面模板、相同用户群和相同时间段内,对比 /products?sort=price 与 /products?sort=popularity 的 LCP、INP 和 CLS。
为什么查询字符串会导致性能回退
查询参数是造成无法解释的性能差异的最常见原因之一。以下是它们如此重要的原因:
CDN 缓存行为
默认情况下,大多数 CDN 会将具有不同查询字符串的 URL 视为独立的缓存条目。/search?q=boots 和 /search?q=sandals 是两个截然不同的缓存键。如果您的搜索结果页面每小时生成数百个独特的查询,那么几乎没有一个请求能从缓存中获取。每位访问者都会冷启动命中您的源服务器。
一些 CDN 允许您在缓存键中忽略特定参数(如 UTM 标签),但这种配置很容易被遗漏。如果 utm_source=email 被包含在您的缓存键中,那么您的电子邮件营销着陆页的缓存命中率将接近于零,每位收件人得到的都是完整的服务器渲染而非缓存响应。这是一个常见且可测量的 LCP 飙升点。
服务端渲染成本
过滤和排序参数通常会触发页面上最昂贵的数据库查询。/products 上的普通产品列表可能被完全缓存。但如果访问 /products?color=red&size=M&brand=Nike&sort=price-asc,同一页面可能需要复杂的查询、不同的响应结构,甚至完全重新渲染。在无法有效缓存过滤结果的页面上,time to first byte 会增加,LCP 也会随之升高。
分页是另一个一贯的痛点。列表的第 1 页通常很快,因为它是默认视图并且被强力缓存。第 10 页或第 50 页极少被缓存,生成速度通常较慢,且通常未经测试。CoreDash 会直接呈现这些差异,无需您去猜测。
参数触发的客户端行为
某些查询参数不会改变服务器响应,但会改变加载时运行的 JavaScript。A/B 测试变体参数、联盟跟踪代码和推荐令牌经常被脚本读取,用于初始化不同的 UI 流程、触发额外的网络请求,或在等待实验配置时延迟渲染。这些参数可能会增加可测量的 INP 成本,如果变体在初次绘制后改变了可见内容,偶尔还会导致布局偏移。
值得调查的常见模式
- 付费流量中的 UTM 参数:来自广告的访问者通常会携带
?utm_source=google&utm_medium=cpc&utm_campaign=...落地。如果您的 CDN 将这些参数包含在缓存键中,付费流量获得的响应将始终比自然流量慢。 - 搜索结果页:简短且热门的查询可能会被缓存。长尾查询或首次查询几乎从不被缓存。对比
?q=nike与?q=blue+trail+running+shoes+mens+size+11,通常会显示出可测量的 LCP 差异。 - 重度过滤器组合:带有多个有效过滤器的电子商务类别页面渲染成本很高,且极少被缓存。如果您的 75 分位 LCP 很高,过滤器组合很可能是一个主要诱因。
- 第 1 页之后的分页:第 2 页及以后的页面通常更慢且更耗费资源。它们通常还包含相同的主图或布局,但无法从上次访问中获得缓存资源的优势。
如何在 CoreDash 中使用此维度
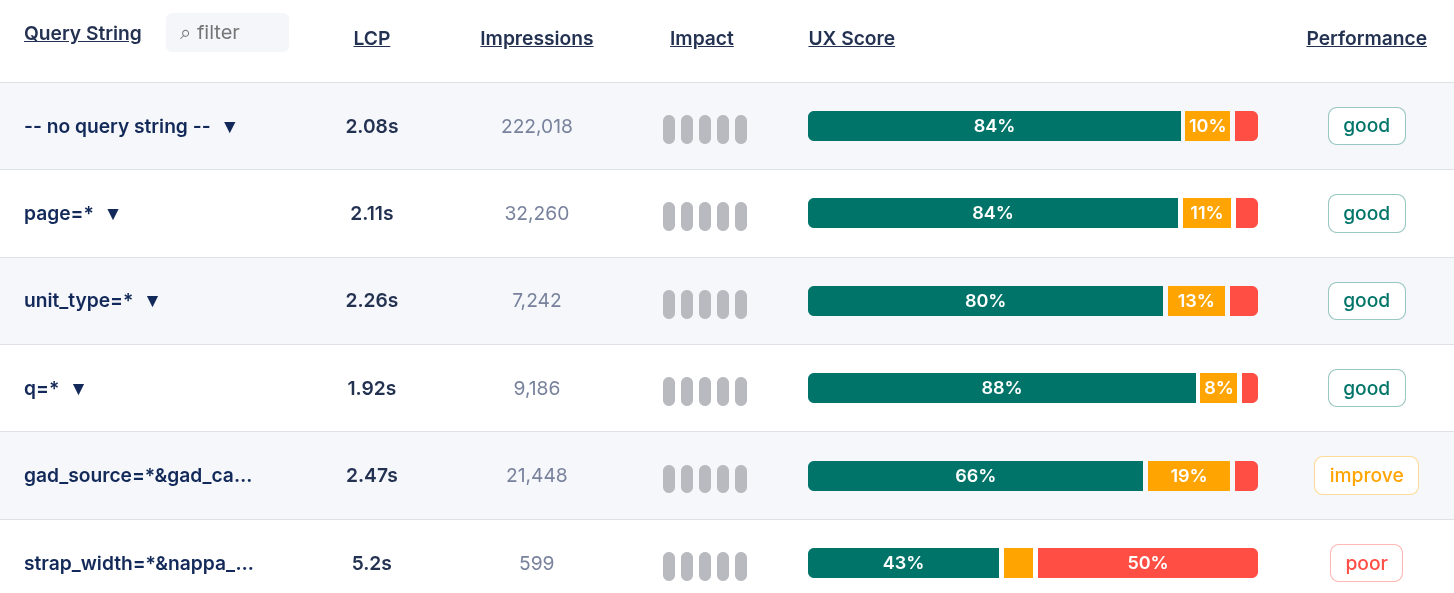
从任何 CoreDash 报告的维度选择器中选择 Query String。表格将显示每个独特的查询字符串及其对应的 LCP、INP、CLS 和访问量。按 LCP 排序以查找最慢的参数组合,或按访问量排序以查找流量最高的变体。
将此维度与 URL 维度结合使用,将分析范围缩小到单一页面模板,然后再比较其查询字符串变体。这种组合可以轻松确认性能问题是出在页面本身还是特定的参数模式中。
Query String 维度属于 CoreDash 中的 Page & Navigation 类别,与之并列的还有 URL、Pathname 和 Navigation Type 等维度。