Core/Dash Entender los paneles de desglose de métricas
Análisis de causa raíz. Diseca las métricas compuestas en sus partes fundamentales para identificar la fuente exacta de la latencia.
Trusted by market leaders · Client results
Entender el panel de desglose de métricas
Las métricas compuestas como el LCP y el INP agrupan múltiples eventos de tiempo distintos. Optimizar la puntuación total requiere aislar estos componentes subyacentes. El panel de desglose de métricas diseca el rendimiento en fases granulares para identificar el cuello de botella específico.
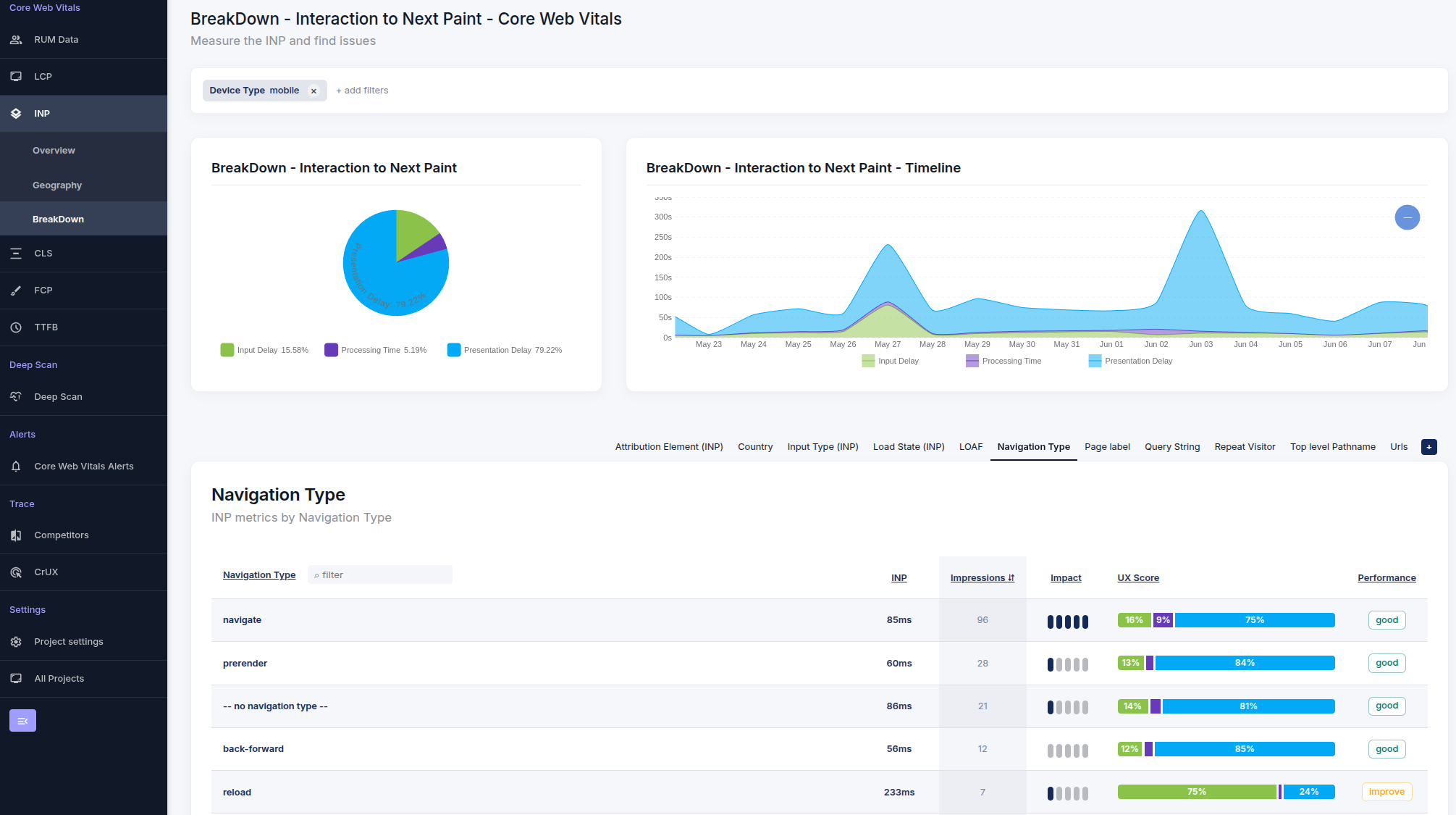
Esta herramienta reemplaza la optimización generalizada por objetivos de ingeniería precisos. Atribuye la latencia al servidor, la red o la ejecución en el cliente.
Anatomía del panel de desglose
El panel ofrece tres vistas sincronizadas para aislar la causa raíz de la latencia:
- Donut de contribución: Visualiza el peso relativo de cada subparte. Responde a la pregunta: "¿Cuál es el factor principal?" Si `Time to First Byte` ocupa el 70% del gráfico, sabes que el problema está relacionado con el backend.
- Línea de tiempo histórica: Muestra la tendencia de los valores absolutos de cada componente a lo largo del tiempo. Úsala para correlacionar cambios de rendimiento con eventos específicos como despliegues.
- Tabla de datos segmentados: Desglosa la métrica por dimensión (URL, dispositivo, etc.). Cada fila incluye una barra de distribución que revela el perfil único de ese segmento, lo que te ayuda a detectar valores atípicos.
Componentes del LCP (Largest Contentful Paint)
El LCP mide el rendimiento de carga. Dividimos esta métrica en cuatro fases:
- TTFB (Time to First Byte): El tiempo de respuesta del servidor. Un TTFB alto indica consultas lentas a la base de datos o falta de edge caching.
- Retraso de carga: El intervalo entre la respuesta HTML inicial y el inicio de la descarga del recurso LCP. Esto mide la latencia de descubrimiento del recurso.
- Tiempo de carga: La duración requerida para descargar el recurso LCP (imagen o fuente) a través de la red. Esto se correlaciona con el tamaño del archivo y el ancho de banda.
- Retraso de renderizado: El tiempo entre que finaliza la descarga del recurso y se pinta en la pantalla. Un retraso de renderizado alto suele indicar el bloqueo del main thread por JavaScript.
Componentes del TTFB (Time to First Byte)
El TTFB sirve como indicador de la capacidad de respuesta del servidor. Este desglose aísla las fases de la conexión de red:
- Espera: El tiempo que pasa el navegador esperando a que el servidor genere una respuesta (procesamiento en el backend).
- Caché: El tiempo dedicado a verificar las cachés locales o intermedias.
- DNS: La duración de la búsqueda del Domain Name System.
- Conexión: El tiempo necesario para establecer la conexión TCP.
- Petición: El tiempo empleado en enviar las cabeceras de la petición HTTP.
Componentes del INP (Interaction to Next Paint)
El INP mide la interactividad. Segmentamos el ciclo de vida de la interacción para localizar el bloqueo del main thread:
- Retraso de entrada: El tiempo entre la interacción del usuario y la ejecución del controlador de eventos. Un retraso de entrada alto significa que el main thread estaba ocupado.
- Procesamiento: El tiempo necesario para ejecutar los callbacks del evento. Esto representa la eficiencia de tu lógica de JavaScript.
- Presentación: El tiempo que tarda el navegador en calcular el diseño y pintar el siguiente fotograma.
Flujo de trabajo de diagnóstico
Sigue esta secuencia para diagnosticar una regresión:
- Cuantifica el cuello de botella: Mira el gráfico de dona para encontrar la subparte dominante. Si el `TTFB` es alto, revisa tu servidor. Si el `Resource Load Delay` es alto, revisa la prioridad de tus recursos.
- Establece la causalidad: Revisa la línea de tiempo para correlacionar el pico con un despliegue o actualización de contenido específico.
- Aísla el contexto: Usa la tabla de datos para ver si este patrón se cumple en todas las páginas o si es específico de una plantilla determinada. Encontrar el patrón es clave para implementar una solución escalable.
Optimizar los Core Web Vitals
Usa estos desgloses para dirigir los tickets al equipo de ingeniería adecuado. Asigna los problemas de TTFB a Backend. Asigna el retraso de carga y el retraso de renderizado a Frontend. Asigna la latencia de DNS/conexión a Infraestructura. Este proceso de triaje optimizado reduce el tiempo de investigación y acelera la resolución.

